论文题目
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node
相关信息
作者与单位
Suhas Jayaram Subramanya(suhas@cmu.edu); Carnegie Mellon University;
Devvrit(devvrit.03@gmail.com); University of Texas at Austin;
Rohan Kadekodi(rak@cs.texas.edu); University of Texas at Austin;
Ravishankar Krishaswamy(rakri@microsoft.com); Microsoft Research India;
Harsha Vardhan Simhadri(harshasi@microsoft.com); Microsoft Research India;
出处与时间
33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada. (人工智能A类会议); 2019
作者拟解决的主要问题
研究背景
近似最近邻算法主要是在索引时间,索引尺寸,搜索时间,召回率等方面进行权衡。基于树的方法一般是生成紧凑索引,这些索引在低维情况下能够快速搜索,但是当维度超过20时,会面临”维数灾难”;基于哈希的方法能够在索引尺寸和搜索时间之间做一个更好的权衡,但它们一般没有利用数据点的分布;基于图的方法能在搜索时间和召回率方面做一个更好的权衡,相比其它索引方法,此类方法有更好的搜索性能。目前,很多应用都需要一个在亿级数据规模上快速精确的搜索算法。
现存解决方案
现存已有两种方案。
一是倒排搜索+数据压缩的方法,比如FAISS和IVFOADC+G+P。这类方法将数据集聚类为 $M$ 个部分,仅将查询 $q$ 与 $m$ ($m \ll M$)个与 $q$ 最近的部分中的点做比较。而且,因为原始数据不适合直接载入内存,这类方法将原始数据使用乘积量化(PQ)的方案压缩,因此,它们具有很小的内存占用,查询延迟很小。不过,由于对原始数据的压缩是有损压缩,它们的召回率是很低的。
二是导航图+分布式的方法,比如NSG。这类方法将数据集划分为一定量个不相交的部分,在每一个部分都建立一个内存索引,每一部分处在不同的机器上。查询时,将查询点同时路由到每一个部分,在各部分并行执行查询,最后,将各部分返回的结果整合到一块选取最近的点作为最终结果。这类方法由于将原始数据载入内存,因此有很大的内存占用,而且,当数据规模增大时,就需要更多的机器,优点是能够实现高召回低延迟。
现存方法的问题
现存大部分方法的搜索过程是完全基于内存的,也就是所有的索引信息都要载入内存,如果将现存的这些完全基于内存算法的索引放在外存中(比如SSD),一个显著的不良后果就是延迟将会很高。如何将高搜索性能的算法和外存结合实现亿级快速高召回的搜索是本文要解决的核心问题。
本文的解决方案
采用具有高搜索性能的近邻图索引,将索引放在SSD上以减轻对内存的依赖。在查询时,通过尽可能少的次数在SSD上的读取原始数据实现快速高精度ANNS。
本文的贡献
- DiskANN可在一个64GB RAM工作站上为十亿规模维度为100+的数据集建立索引,实现不超过5ms 1-recall@1为95%以上;
- 新图基算法Vamana,比NSG和HNSW有更小的直径(路径跳数),使DiskANN最小化顺序读取磁盘的次数;
- 完全基于内存的Vamana实现比当前最优的图算法NSG, HNSW更优搜索性能;
- 将数据集重叠划分为多个区域,在每个区域中建立小Vamana,然后再归并得到一个索引,它的性能与在整个数据集构建索引相当(不能完全载入内存的大规模数据);
- 将Vamana与矢量压缩方案结合,构建DiskANN系统,图索引和原始数据存在SSD中,压缩索引存在内存中。
论文主要研究内容
- 如何构建一个适合放在外存中的具有高搜索性能的近邻图结构;
- 如何在将内存搜索算法与外存结合实现在单机上亿级规模数据的快速高召回检索。
论文使用的方法
Vamana近邻图算法
选边策略
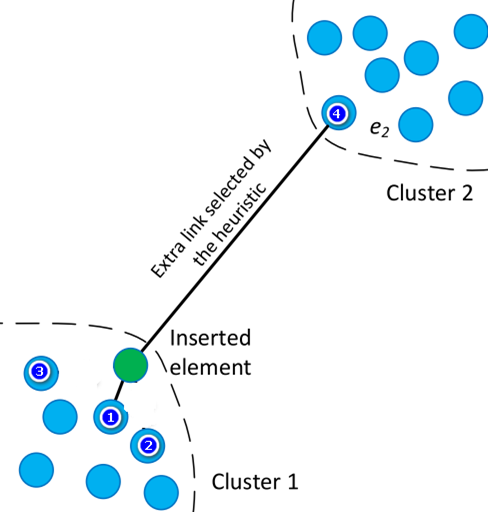
现存的一些近邻图算法选边策略是这样的。如图1所示,现在要给绿色的点选邻居,假设要给他选两个邻居,从构建一个精确的近邻图的角度,一定是选离绿色点最近的两个点(点1,点2)。这样得到的图确是精确了,但是可能会造成邻居集中在一块的现象,不能在各个方向均匀分布。实验证明,一个精确的近邻图并不一定是最适合ANNS的。
因此,从ANNS角度去构建一个近邻图就不能只考虑选最近的邻居。继续看图1,可以采用一种启发式的策略,先把离绿色点最近的点1选中(加入绿色点的邻居集),然后对点2进行一个判断:若d(1,2) < d(2,绿点),则点2不加入绿点的邻居集,后面依次对点3及左下角的其它点进行判断(顺序是离绿点由近到远),最后判断点4时,由于:d(4,1) > d(4,绿点),故点4加入绿点邻居集。HNSW的启发式选边便是这样的(详见:入口)。
现在,我们考虑一种极端的情况,数据集中的点都在一条线上,看图2。当对这样的数据集执行上述图1所示的选边时,每个点只能和离它最近的两个点相连。在这样的图上执行ANNS时,会导致平均跳数很高,如果将这样的图配合外存执行搜索,可能会导致多次外存访问,从而造成高延迟。

本文对这种比较固定的选边策略稍稍改进,增加一个参数$\alpha$,就图2而言,a离b最近,a直接加入b的邻居集,接着判断c,由于d(a,c) > d(b,c),c加入b的候选集,按之前的策略,直线上的其它点就像被a和c屏蔽掉一样不会再与b连边,因为d(a,others) < d(b,others)或者d(c,others) < d(b,others)。现改动一下判断条件:$\alpha$d(a or c,others) > d(b,others),通过调节$\alpha$,从而可增加一些长边。
完整构图过程
- 随机初始化一个出度为R的图G;
- 计算图G的导航点s(近似质心);
- 为每一个点p重新选邻居,候选集为从s点出发贪婪搜索访问到的所有点;
- 对p的邻居添加反向边,当邻居的出度超过上界时,对邻居执行裁边;
- 对步骤3和4执行两遍,第一遍𝜶=𝟏,第二遍𝜶≥𝟏。
图3是原文里面的图,这是使用Vamana在二维空间构图的可视化过程。文章没有描述清楚这个图,合理推测作者想要表达的意思应该是这样的:第一行是第一遍构图过程(𝜶=𝟏),第二行是第二遍构图过程(𝜶≥𝟏)。直观可见,开始初始化的图很稠密,经过第一遍的选边图变得很稀疏,有长边但是并不多,接着第二行,经过第二遍的选边,肉眼可见增加了很多长边。

DiskANN
索引设计
DiskANN索引设计的基本思想是:面对亿级规模的数据,将图索引和原始数据存在SSD中,搜索时,需要访问某点的邻居,就从SSD中读取。在这个基本思想下,有两个突出的问题:
- 如何在十亿规模数据上构建图索引;
- 原始数据不在内存中,如何比较点的距离。
针对第一个问题,之前NSG的解决方案是,划分数据集为多个小子集,在每个子集上构建图索引,搜索在少量几个离查询更近的子图上执行。这种方案很简单,要想达到低延迟,在搜索时需要多个机器并行执行搜索,最后将各个机器查询的结果归并到一起排序。很明显这种方式对硬件要求很高。
本文对第一个问题的解决方案是划分数据集为多个小子集,将每个点分配到离之最近的两个子集中,在每个子集中建立图索引,最后通过简单的边归并将所有子图归并为一个图。最后的实验也证实了这种方案与在整个数据集中建图的结果就最终的搜索性能而言是相当的。这种方案硬件成本很低。
针对第二个问题,对数据集中的每一个原始向量使用量化技术压缩,搜索时,将压缩向量载入主存,图索引和原始向量存在SSD中;搜索时,将查询向量同样压缩,通过压缩向量之间的距离近似原始向量距离。
索引布局
总体布局是压缩向量载入主存,图索引和原始向量存在SSD中。在SSD中,在SSD中,某一点的原始向量和它的不超过R个邻居的ID存在一起(原因请往下看),不足R个邻居的位置用0填充。
集束搜索
如果按照常规的贪婪算法,每访问到一个点就从SSD中将该点的邻居取出,这种方式访问外存次数等于贪婪搜索访问点的个数,导致多次的访问SSD,多次访问SSD会增加搜索延迟。而从SSD中访问少量的随机部分与访问一个部分花费的时间几乎相同。因此,本文采用集束搜索,一次从SSD中载入未访问集中的W(4或8)个点的邻居集,但是W并不是越大越好。
原始向量重排序
使用乘积量化对原始向量的压缩是有损压缩,使用压缩向量进行距离计算必然会有一定误差。而若完全使用原始向量进行距离计算会导致对SSD访问次数增加。本文的解决方案是,将每个点的原始向量与其邻居ID在SSD中存放在一起,载入邻居时,将原始数据一起载入,最后进行精确距离计算重排序。这样一步是高召回率的主要保证。
论文的创新点
- 构图时,选边策略增加了一个参数,这使选边过程更灵活,能够随不同的数据集进行调整,而且还可产生一些有益的长边;
- 将近邻图算法与SSD结合形成一个基于SSD和高效内存算法的DiskANN,而且还将量化的方案参与其中,充分利用了各种方案的优势,避免了各自的不足,从而实现在单机上的高效亿级搜索。
论文的结论
- 比当前最优HNSW和NSG更优的Vamana内存图搜索算法;
- 比当前最优单机亿级搜索算法FAISS和IVF-OADC+G+P更优的DiskANN(基于SSD)的高召回、低延迟和低内存占用搜索算法;
- DiskANN将图算法的高召回、低延迟与压缩方法的低内存占用、可扩展性结合在一起。
我的观点或思考
- ANNS的四大流派各有各的优点和缺点,图算法搜索性能最好,但是它对原始数据非常依赖,而且,构建成本相比其它方法也比较高。与之相反,量化方法搜索性能一般(召回率不会达到很高),但其不依赖原始数据,内存占用很低;通过某种框架将各流派方案组合起来,实现一个优势互补,这是一个值得考虑的内容;
- 图索引构建过程的核心还是选边问题,什么样的选边才是更适合ANNS的?选边候选集怎样去获取更好?

